使用 SQL 語法來操作資料
前言(SQL 用途)
在這個系列的什麼是資料庫?這篇文章中,有介紹到資料庫管理系統與資料庫的關係,並且知道資料庫類型分為關聯式跟非關聯式資料庫。
接下來這個系列將會先專注在關聯式資料庫,而關聯式資料庫主要是使用 SQL(Structured Query Language)這樣的語言來操作和管理資料。如下方圖片所示,我們可以了解 SQL 就如同溝通橋樑,它讓我們能夠向資料庫管理系統發送指令,然後對資料進行新增(CREATE)、讀取(READ)、編輯(UPDATE)和刪除(DELETE)等操作。(取每個英文的首字,就是網頁開發常看到的用詞 CRUD)

在這篇文章中,將會使用 SQL 基礎語法來練習創建資料表(表格),並對資料做 CRUD 的操作。這邊也會先使用 SQLite Online 這樣的線上模擬工具來做練習。
SQL 語法與操作範例
SQL 的入門語法並不會太困難,因為它的語法使用了簡單的英文字詞。例如使用 SELECT 用來選取資料、FROM 指定資料來源、CREATE 用來創建資料表等。這些語法是很貼近其字面意思,因此在操作資料時相對容易理解每個語法的功能。
在接下來的範例中,我們將以社交媒體平台為主題,透過 SQL 語法來創建用戶(users)資料表和貼文(posts)資料表,並建立一個簡單的關聯。這兩個資料表之間的關聯,能讓我們追蹤每篇貼文的發文者。資料表範例如下:
users 用戶資料表:
| id | username | |
|---|---|---|
| 1 | Alice | alice@example.com |
| 2 | Bob | bob@example.com |
| 3 | Charlie | charlie@example.com |
posts 貼文資料表:
| id | user_id | title | content | created_at |
|---|---|---|---|---|
| 1 | 1 | 歡迎來到我的部落格 | 這是我的第一篇文章 | 2024-10-22 10:30:00 |
| 2 | 1 | 我的第二篇文章 | 這裡有一些新的更新 | 2024-10-22 12:00:00 |
| 3 | 2 | Bob 的自我介紹 | 哈囉,我是 Bob! | 2024-10-22 13:45:00 |
| 4 | 3 | 對於程式設計的想法 | 程式設計既有趣又困難 | 2024-10-22 14:00:00 |
資料庫常見用詞
在進到 SQL 的語法學習跟操作之前,我們需了解一些在資料庫中常看到的用詞:資料庫(Database)、資料表(Table)、欄位(Column)、列(Row)。
- 資料庫:資料庫是用來儲存和管理所有資料的地方,它可以包含多個不同的資料表。可以將其想像成 Google 試算表本身,試算表內部可能有多張工作表,各自管理不同類型的資料。
- 資料表:資料表是由欄位(Column)和列(Row)所組成的結構,用來儲存特定的資料。可以想像成 Google 試算表中的工作表,每一個工作表都負責管理某類特定的資料,例如用戶資料或貼文資料。
- 欄位:資料表中的每個「欄位」代表一種類型的資料,例如在上方的 users 資料表中,欄位包含
id(用戶識別)、username(用戶名稱)、email(電子郵件地址)等。每個欄位定義了這張資料表中要儲存的資料類型。 - 列:資料表中的每一「列」代表一筆完整的資料記錄。每一筆資料記錄都會對應到資料表中的每一個欄位,並且儲存具體的值。以 users 資料表為例,第一筆資料的
id是1、username是Alice、email則是alice@example.com。
users 資料表的 CRUD
接下來要進到重頭戲了,這邊會以 SQL 語法來操作 users 資料表的 CRUD。
首先打開前面提到的 SQLite Online,在面板的左方我們可以選擇要用哪個資料庫系統,這邊是選用 PostgreSQL。而程式碼輸入區塊跟 Run 按鈕是很常會使用到的。
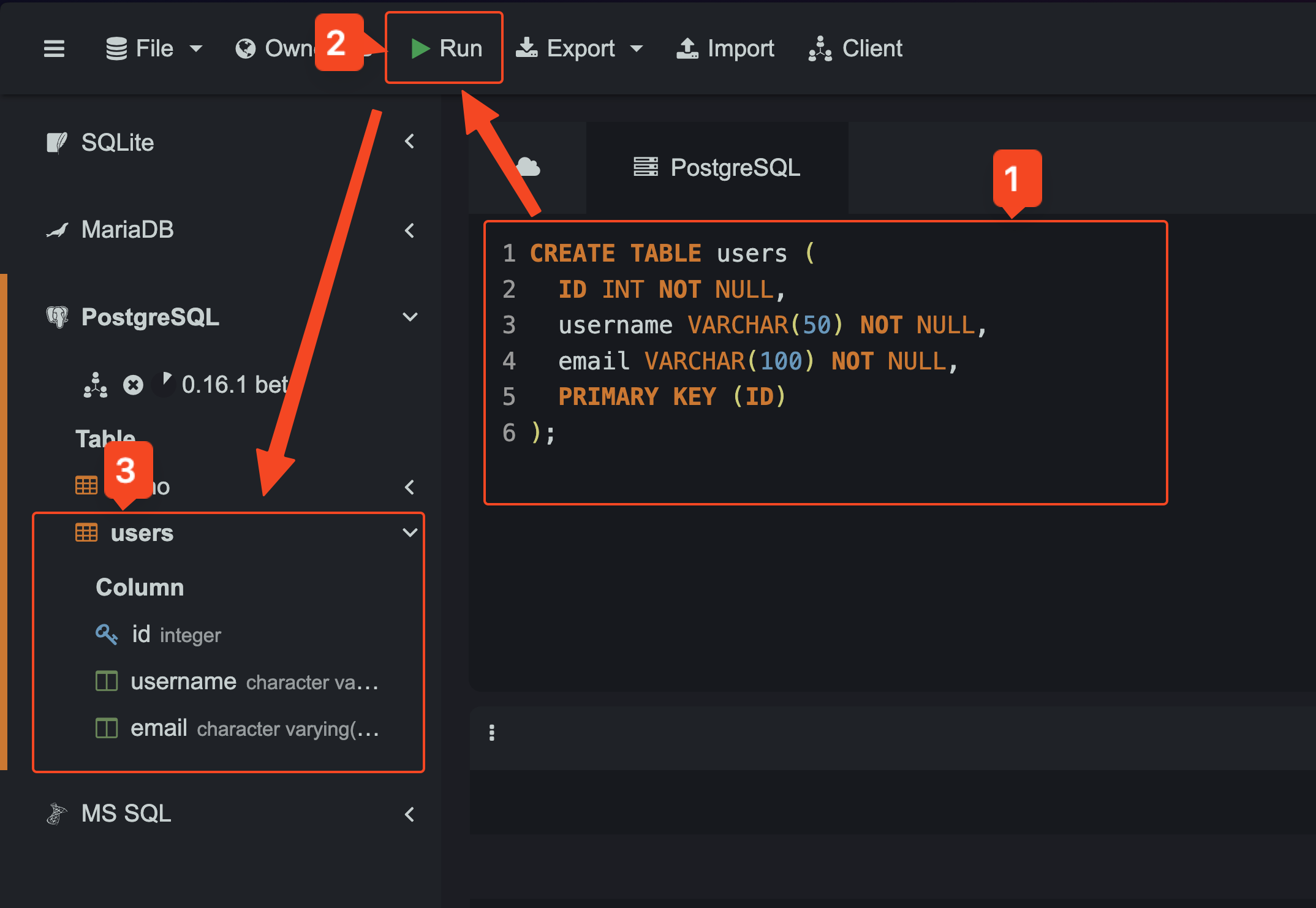
CREATE 創建 users 資料表
然後要來創建一個 users 的資料表。在 SQL 的語法,我們可以使用 CREATE TABLE 資料表名稱 來建立新的資料表,並且在 () 去定義每個欄位的名稱以及對應的資料型別。關於欄位對應的資料型別,可以參考 SQL Datatypes。
1 | |
id INT NOT NULL:這個欄位表示每個 user 的唯一識別,而INT型別表示它是整數,NOT NULL表示這個欄位必須有值,不能為空。username VARCHAR(50) NOT NULL:為用戶名稱的欄位,使用VARCHAR(50)來定義這個欄位可以存放最多 50 個字元的字串,同樣NOT NULL表示此欄位不能是空值。email VARCHAR(100) NOT NULL:用戶的電子郵件,使用VARCHAR(100)來允許最多 100 個字元的字串,也同樣不能為空。PRIMARY KEY (id):指定id是這個資料表的主鍵,它就像是每一筆資料的「身分證」,具有唯一性。(指定某個欄位為主鍵,即是唯一的概念,表示這個欄位的值不能重覆。)
相關操作如下圖,輸入程式碼後點擊 Run 按鈕,我們就能在左方看到 users 資料表了。
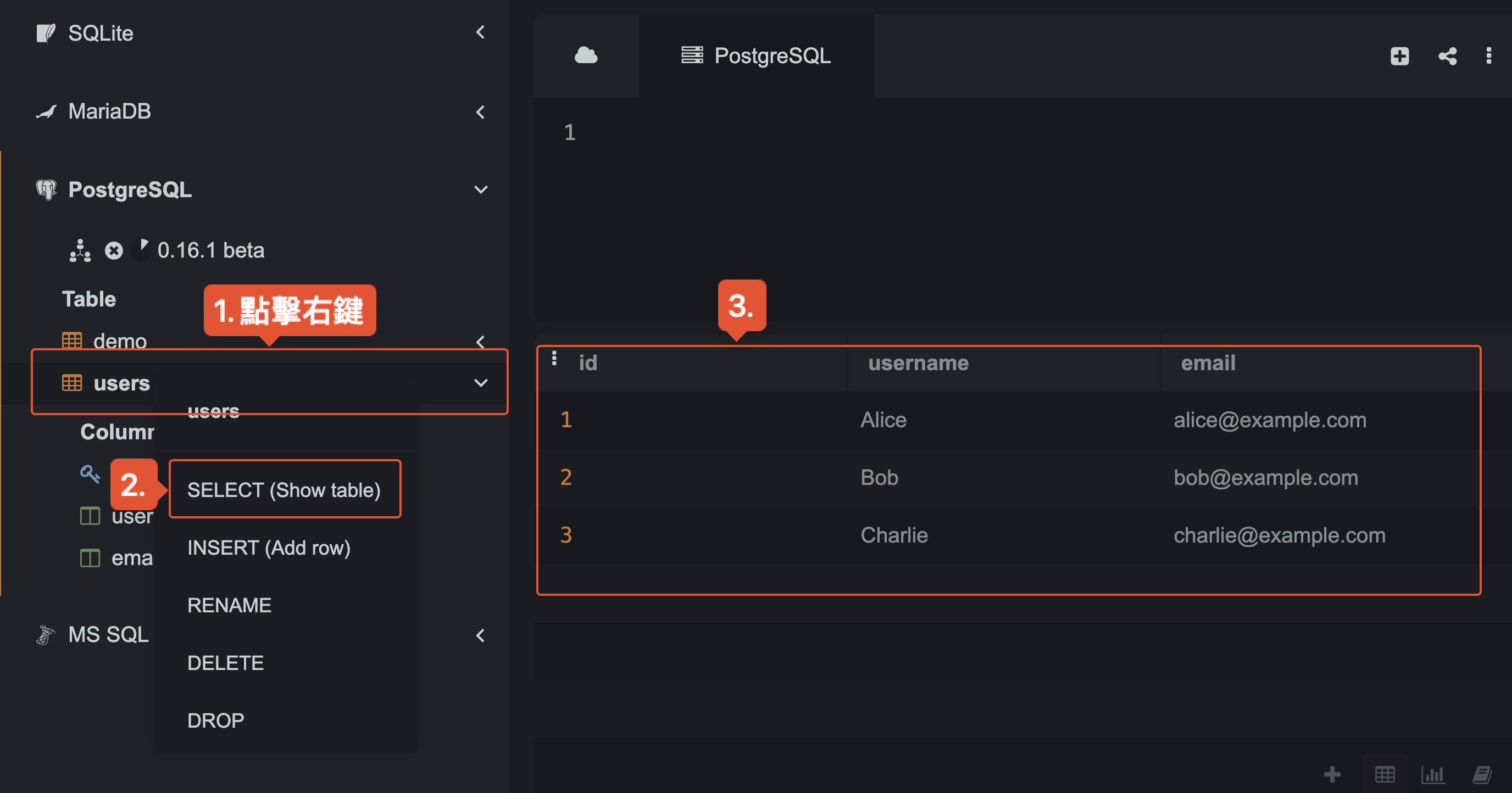
INSERT 在資料表新增資料
在上方的內容中,我們成功建立了 users 資料表,不過目前還沒有相關資料。而我們可以使用 INSERT INTO 語法,將資料新增到資料表中。
1 | |
INSERT INTO users (id, username, email):這表示我們要將資料新增到users資料表中,並且指定要帶入資料的欄位名稱。VALUES (1, 'Alice', 'alice@example.com'):這是我們提供給指定欄位的值。id為 1,username是'Alice',email為'alice@example.com'。(這邊需注意字串的值要使用單引號,如果使用雙引號則會出錯)
如果資料表欄位跟值的順序一致,則也可以省略欄位名稱,直接使用 INSERT INTO users VALUES (...) 的簡化寫法:
1 | |
也可以一次新增多筆資料:
1 | |
在新增資料的操作上(程式碼跟 Run 按鈕),如果沒有出現錯誤,則我們依照下圖的步驟就可看到新增成功的資料哩!
READ 讀取資料
在上一個段落新增資料成功後,當我們在左邊選單點擊 SELECT(Show table)這個按鈕時,除了能看到帶有資料的表格,也會在程式碼區塊看到以下語法。
1 | |
SELECT *:選擇資料表中的所有欄位跟相應資料。FROM users:指定從users資料表中(選取資料)。
我們也可以從資料表中,只選取特定的欄位來做呈現,或者根據某個條件來篩選呈現的結果。
1 | |
1 | |
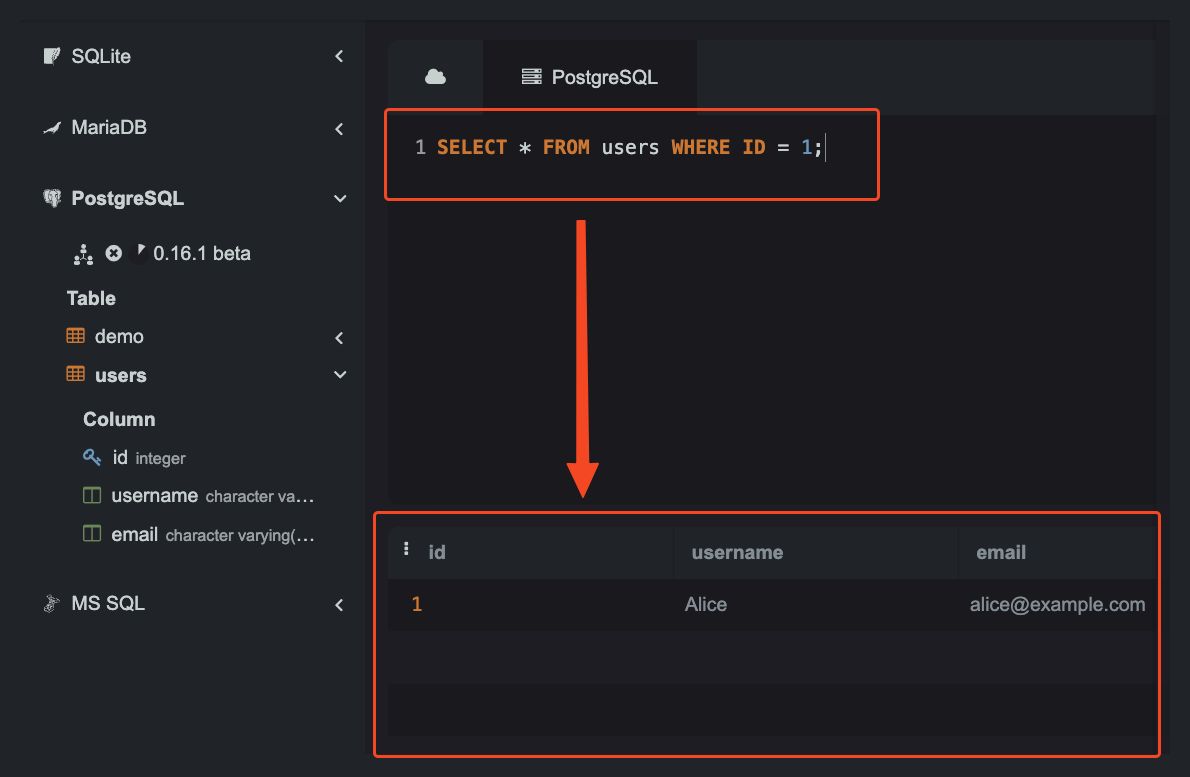
SELECT * FROM users:從 users 資料表中,選取全部欄位跟相應資料。WHERE id = 1:在選取users資料表所有欄位資料的基礎上,篩選出id值為 1 的那筆資料。
讀取資料篩選 id = 1 的示例:
UPDATE 更新資料
在資料表中,有時我們需要去調整某些資料,例如修改使用者的電子郵件。這時我們就可以使用UPDATE 語法來更新特定欄位的值,如下方範例:
1 | |
UPDATE users:我們要更新的資料表為users。SET email = 'alice.new@example.com':將email欄位的值更新為'alice.new@example.com'。WHERE id = 1:指定篩選條件,更新id為 1 的那筆資料,只有這筆資料的email值會被更新。(注意:若省略WHERE條件,則所有資料列的email欄位都會被更動。)
更新示意: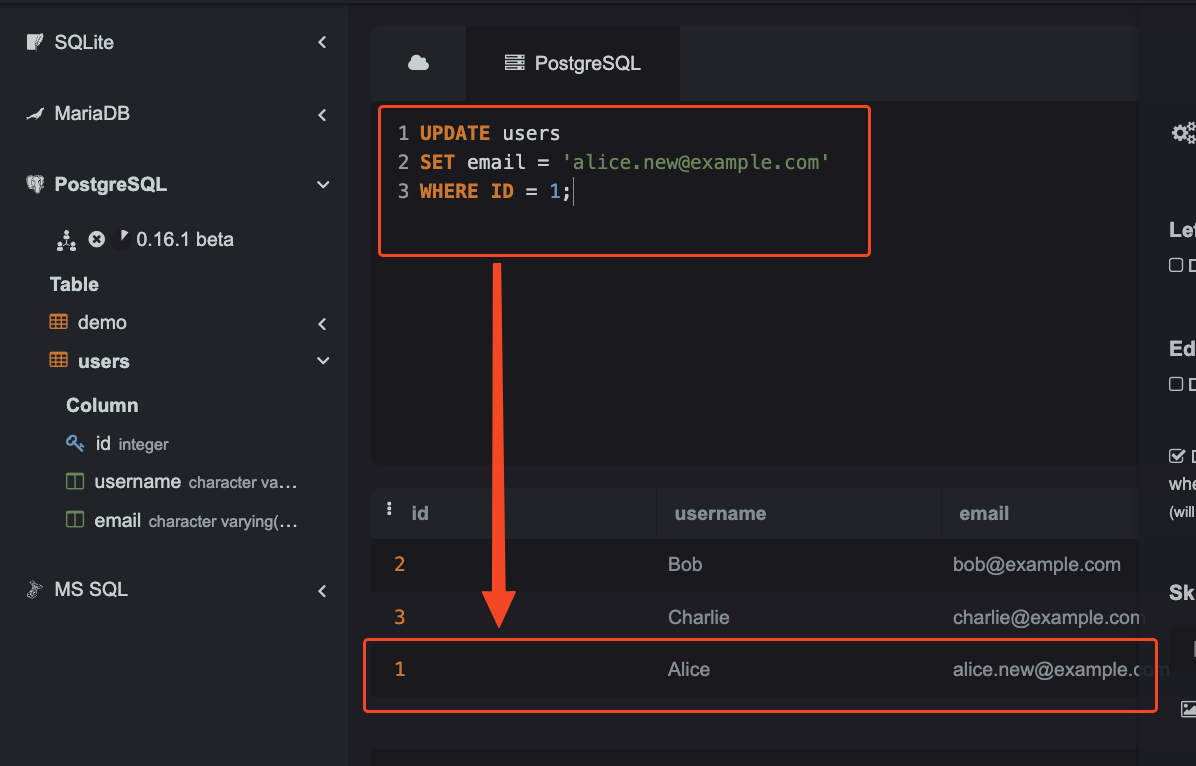
DELETE 刪除資料
以上討論了怎麼創建資料表(CREATE)跟新增資料,以及怎麼去讀取(READ)跟更新(UPDATE)資料表中的資料。最後我們要來看刪除資料的部分,在 SQL 是使用DELETE 語法來刪除。
1 | |
DELETE FROM users:我們要刪除資料的來源是users資料表。WHERE id = 2:指定篩選條件,僅刪除id為 2 的那筆資料。(注意:省略WHERE條件會刪除users表中的所有資料。)
資料表關聯
在前面的內容中,我們以 users 資料表來操作跟了解 SQL 的 CURD。
接下來我們要創建另一個 posts 資料表,並把這兩張資料表做個關聯。
創建 posts 資料表
1 | |
id INT NOT NULL:此欄位作為每篇貼文的唯一識別,而INT型別表示它是整數。user_id INT NOT NULL:此欄位用於儲存發表貼文的用戶 ID,是設計來關聯user資料表中的id欄位。INT型別表示它是整數。title VARCHAR(50) NOT NULL:貼文的標題欄位,VARCHAR(50)定義這個欄位可以存放最多 50 個字元的字串。content TEXT NOT NULL:貼文的內容欄位,TEXT型別適合儲存大量的文字內容。created_at TIMESTAMP NOT NULL DEFAULT NOW():用來記錄貼文的建立時間,TIMESTAMP型別提供日期和時間的紀錄,DEFAULT NOW()設定預設值為當前時間(即自動生成)。PRIMARY KEY (id):指定id欄位為這個posts資料表的主鍵,用於唯一識別且不會重覆。FOREIGN KEY (user_id) REFERENCES users(id):指定user_id為外鍵,連結到users資料表的id欄位,以建立貼文與使用者之間的關聯。外鍵是用來在不同資料表之間建立關係,其所參照的欄位必須是目標表的主鍵(Primary Key)。
註:NOT NULL 表示此欄位必須有值且不能為空,不再重複於每個欄位說明。
新增資料
以下我們使用 INSERT INTO 在 posts 資料表新增了四筆資料。其中 user_id 欄位的值,以 1 來說是對照 users 資料表中 id 為 1 的用戶(Alice)。
1 | |
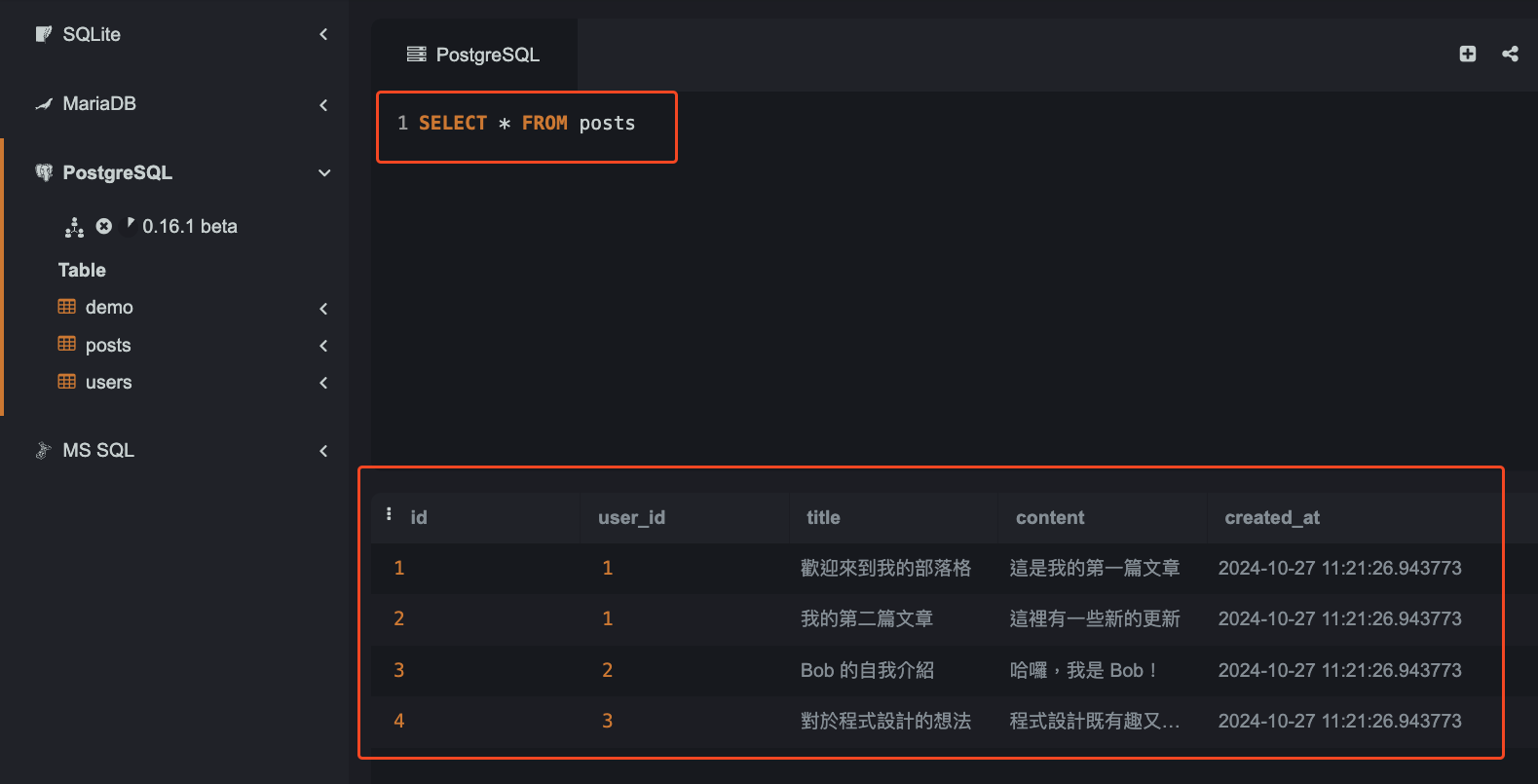
補充說明:created_at 欄位的時間是根據當前時間自動生成的。不過,由於 SQLite 預設使用協調世界時間(UTC)為基準,因此生成的時間會與台灣時間(UTC+8)有 8 小時的時差。此部分與本文主軸無直接相關,因此僅做簡單說明,如需顯示台灣時間,可使用下方程式碼手動添加時區調整:
1 | |
與 users 資料表關聯
資料表的互相關聯中,會使用 JOIN 語法來合併多張資料表的數據,讓我們可以一次從不同資料表中取出所需數據,而不必分別查詢各個資料表。主要的 JOIN 類型包括 INNER JOIN、LEFT JOIN、RIGHT JOIN 和 FULL JOIN 等。
INNER JOIN:為預設的關聯方式,只選取出資料表中「雙方都有資料」的部分。LEFT JOIN:會把左邊表格(JOIN指令之前的那張表)的所有資料都取出來,並且顯示右邊表中符合的資料;如果右邊表沒有符合的資料,會顯示空值。RIGHT JOIN:和LEFT JOIN類似,只是它會取出右邊表格的所有資料,並顯示左邊表格中符合的資料。如果左邊表沒符合的資料,則顯示空值。FULL JOIN:把左右兩邊的表格全部取出,並將彼此有符合的部分對應好。若其中一邊沒有符合的資料,也會顯示空值。(MySQL 不支援)
簡單來說,INNER JOIN 專注在「兩張表都有的資料」,而 LEFT JOIN 和 RIGHT JOIN 分別會保留一邊表格的所有資料;FULL JOIN 則顯示兩邊所有的資料。
以下將使用 INNER JOIN 語法,依據 posts 資料表中的 user_id 欄位跟 users 資料表中的 id 欄位進行關聯,來呈現每則貼文所屬的用戶資料。
1 | |
SELECT users.username, users.email, posts.title, posts.content, posts.created_at:指定要顯示的users和posts欄位。FROM posts:指定主資料表為posts,作為查詢的基礎。INNER JOIN users ON posts.user_id = users.id:使用INNER JOIN將users和posts關聯,依據user_id和id建立關聯,僅顯示符合條件的資料。
關聯結果圖: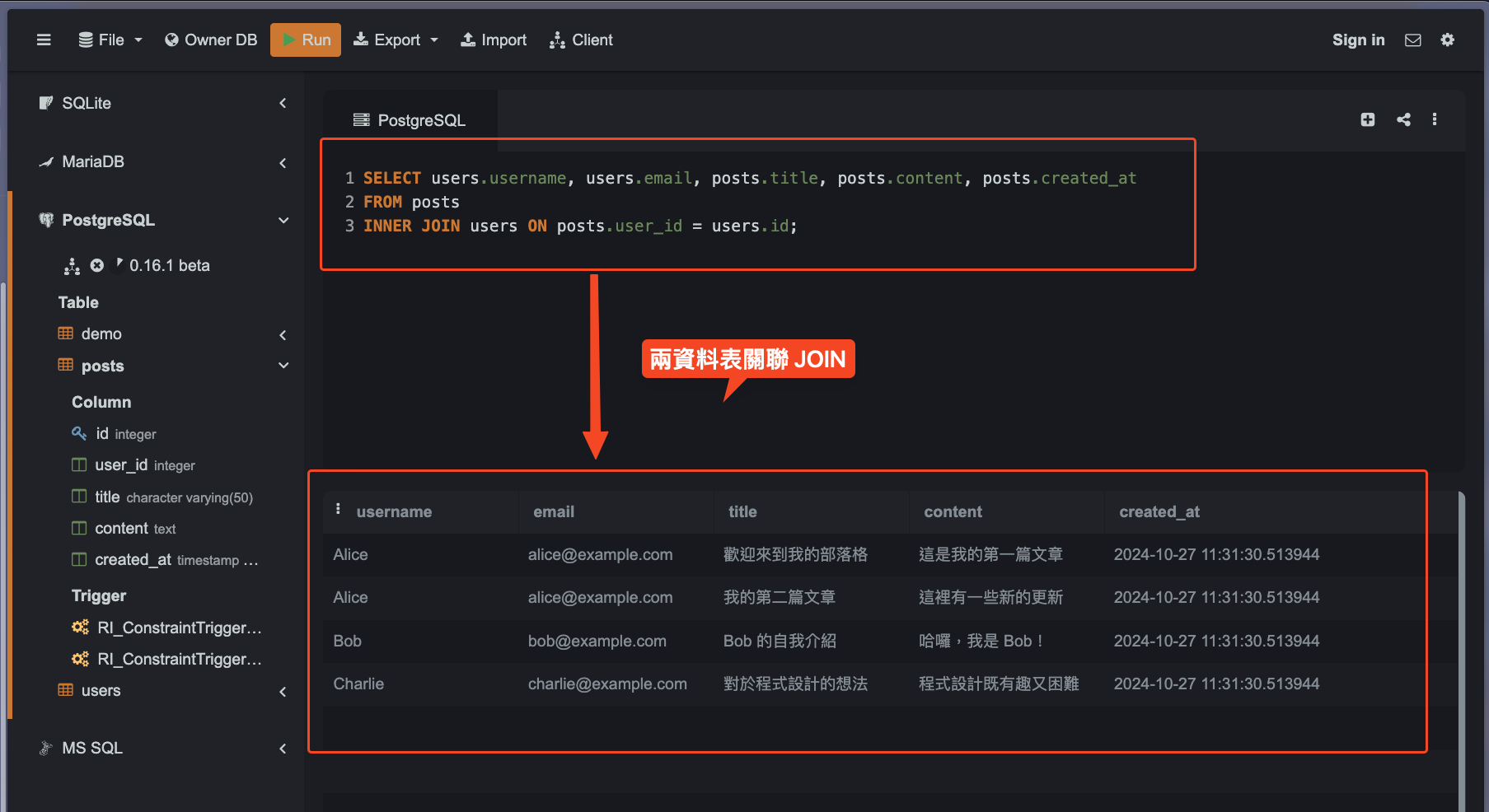
結尾
這個系列的下一篇預計是 PostgreSQL 的討論。近期在規劃上,還會加上 React 的複習(Side Project),加上最初的 TypeScript 學習系列,所以整體的速度也許會慢一些。
這個前端到後端系列,因為後端知識相對較為不熟悉,所以產出文章時會盡力去驗證內容是否有錯誤;假如有看到錯誤,還請不吝點出指導,感謝 🙏
(題外話,最近在思考程式文章的篇幅或呈現方式,是不是要做些調整。例如把篇幅拆的更小一些…🤔)
參考資料:
Photo by Safar Safarov on Unsplash